
新闻动态
NEWS
求是缘半导体周要闻-莫大康(2026.3.30)
来源:
|
作者:芯缘
|
发布时间: 2026-03-31
|
72 次浏览
|
🔊 点击朗读正文
❚❚
▶
|
分享到:
AI芯片十年路线图
定位:AI与硬件协同演进的十年战略蓝图,解决当前“算法适配旧硬件、硬件跟不上新模型”的割裂问题。
训练/推理效率提升1000倍
构建节能、自优化、云端-边缘-物理AI无缝协同的系统
普及先进AI基础设施,兼顾公平与可持续
芯片架构革命(以内存为中心)
存内计算(PIM):计算单元嵌入内存,减少数据搬运,大幅提效降功耗
3D堆叠+近存计算:HBM4e、3D芯片堆叠、小芯片(Chiplet)异构集成
专用架构:GPU/TPU/NPU/模拟AI/光子/神经形态处理器多元并行
光互联(硅光):替代电互联,带宽400Tb/s+,解决通信瓶颈
超大规模扩展:NVLink 576光互联,支持百万级GPU集群,支撑AGI训练
液冷+高密度机架:GB200 NVL72、Rubin平台等机架级液冷方案
大小模型共生:云端大模型做“教师”,边缘小模型轻量化推理,端云协同
自改进系统+去中心化AI代理:硬件自适应优化、多智能体协同
训练-推理统一架构:消除训练与推理的硬件鸿沟,统一优化路径
极致能效:从芯片到数据中心全链路降功耗,解决AI能耗不可持续问题
公平获取:开放基础设施、降低门槛、培养跨学科人才
以人为本:安全、隐私、伦理嵌入硬件设计
短期(1–3年):Blackwell→Rubin架构落地;光互联商用;端云协同优化
中期(4–7年):存内计算规模化;3D集成成熟;自优化系统部署
长期(8–10年):光子/神经形态计算突破;千倍效率达成;AGI级基础设施就绪
2026年半导体涨价已成常态,谁在狂欢?谁在承压?
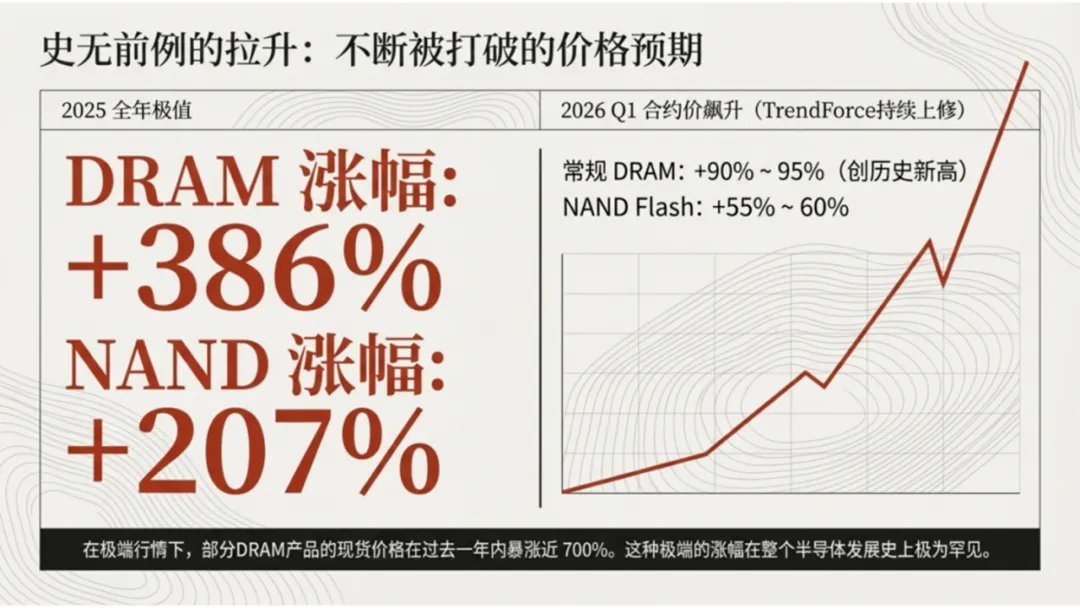

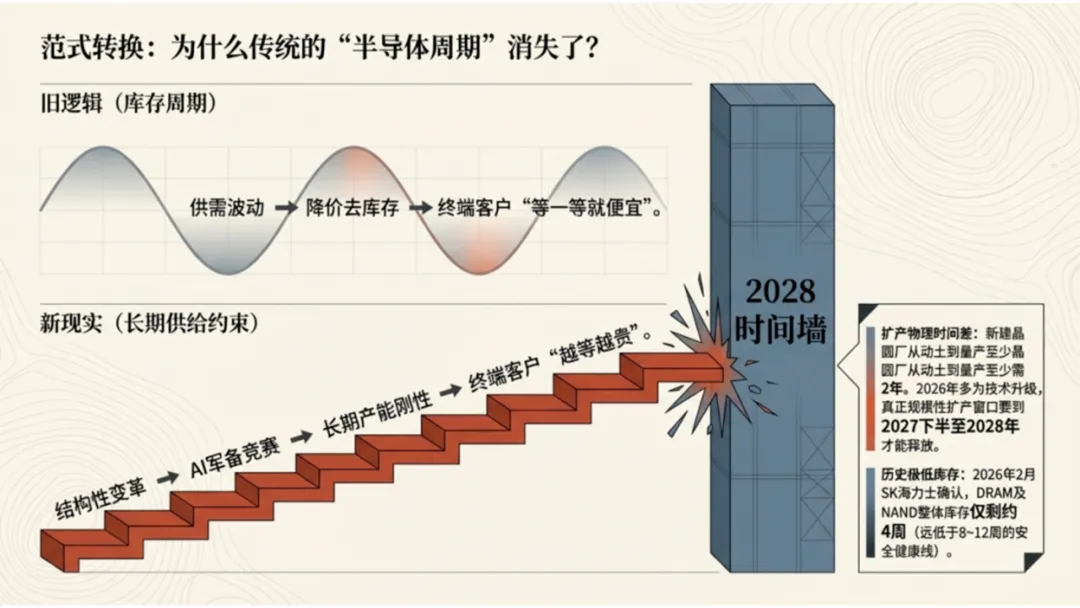

全球半导体业可能超长周期一直到2028年
AI算力超级周期(最强引擎)
从训练→推理爆发,2026年推理占比超70%,带动GPU、HBM、先进逻辑、光互联全链需求 。
云厂商/AI公司资本开支持续上修:Meta、AWS、OpenAI等2026–2028年AI基建投入超3000亿美元 。
供给刚性:晶圆厂建设周期2–3年,2026–2027年新增产能有限,HBM良率仅30%–40%,结构性短缺持续。
DRAM/NAND库存历史低位(仅4周),头部厂商控价保利润。
HBM挤占25%–35%通用DRAM产能,供需失衡延续到2027年底。
2026年存储市场增速或达90%,成为行业第一增长极 。
台积电、三星、英特尔、格芯等先进制程(3nm/2nm)大规模扩产,设备订单饱满 。
中国成熟/先进制程同步扩产,国产替代加速 。
AI需求不及预期:云厂商/AI公司盈利不及预期、资本开支砍单;推理需求落地慢于预期。
宏观与资金压力:全球经济衰退、利率高企、AI公司债务/融资压力上升。
产能过剩风险:2027年底–2028年存储/成熟制程集中投产,价格战风险上升。
地缘政治:出口管制升级、供应链断裂、贸易摩擦加剧 。
马斯克的TeraFab成功几率是多少?
意法半导体华虹代工STM32 MCU规模量产
三星代工迎来大逆转,接连拿下NVIDIATeslaAMD大单
全球第一中国AI大模型调用量达4.69万亿Token
安谋科技CPU成功推出对于中国半导体业的意义
本土团队主导研发:星辰CPU由安谋中国本土团队设计,本土技术占比超90%,完全适配中国场景。
中国市场是最大基本盘:国内授权客户超460家,累计芯片出货450亿+;自研CPU客户235+,自研芯片出货14亿+,中国贡献绝大多数营收与落地案例。
本土需求驱动产品定义:聚焦AIoT、车载、工业、穿戴等中国高速增长赛道,解决端侧算力-功耗-面积矛盾,是为中国市场“量身定制” 。
本土芯片厂快速落地:灵动微电子、兆易创新、华大半导体等230+本土设计公司采用星辰CPU,快速流片量产,形成IP→芯片→终端闭环。
全产业链协同:联动工具链(SEGGER)、软件、终端、车厂,构建中国特色AIoT生态,降低国产芯片门槛 。
政策与资本加持:契合国产替代、自主可控战略,获得地方与产业资本支持,加速研发与生态扩张 。
供应链安全刚需:外部技术管制加剧,本土自研CPU成为国产芯片“安全底座”,安谋星辰填补关键缺口。
端侧AI爆发:中国在智能家居、智能汽车、工业物联网的端侧AI需求全球领先,星辰CPU的Helium向量AI加速精准匹配 。
双轨创新路径:安谋以Arm全球生态+本土自研双轮驱动,既兼容国际标准,又满足中国差异化需求,形成独特竞争力 。
技术自主:提供自研CPU IP,提升本土芯片设计能力,减少对海外单一IP依赖。
产业赋能:让低成本MCU具备AI能力,加速中国AIoT、车载、工业智能化落地 。
生态升级:与“周易NPU、山海SPU、玲珑ISP”形成全栈自研IP矩阵,支撑中国从“应用大国”走向“技术强国”。
Arm造芯为何下场与客户竞争?
END
Copyright © 2021-2031,www.xy-semi.com.cn,All rights reserved版权所有 © 江苏芯缘半导体有限公司官网 未经许可 严禁复制 建议使用1366X768分辨率浏览本站
ICP:苏ICP备2022006250号